
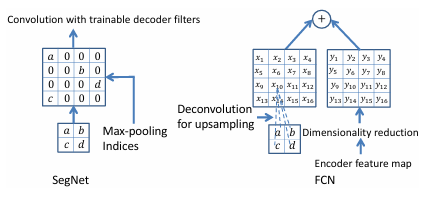

segNet
- 딥러닝 기반의 이미지 분할 모델이면 Fully-Convolutional-Network에서 영감을 받은 모델
- 특히, 효율적인 메모리 사용과 빠른 추론 속도를 목표로 설계함.
- 주로 장명 이해 및 semanic segmentation에 사용
- 장점
- 메모리 효율성
- max pooling 인덱스만 저장하여, 메모리 사용을 줄이고 효율적인 연산을 하게 해줌
- FCN처럼 고해상도 feature map을 전체 저장할 필요 없음.
- max pooling 인덱스만 저장하여, 메모리 사용을 줄이고 효율적인 연산을 하게 해줌
- 추론 속도
- 상대적으로 단순한 구조와 효율적인 unpooling 방법으로 실시간 응용이 가능
- 공간 정보 보존
- max-pooling 인덱스를 사용해서 upsampling 시에 위치 정보를 복원하니 FCN보다 저 정교한 경계 분할이 가능
- 메모리 효율성
- 단점
- 세부 복원의 한계
- 단순히 max-pooling index를 사용하니, u-net같이 skip connection을 활용한 디코딩에 비해서 세밀 복원이 부족함
- 디른 최신 모델에 비해 복잡한 경계 처리가 떨어짐
- 세부 복원의 한계
- 작동 원리...
- encoder 단계 ( 입력 이미지에서 특징을 추출하기 위한 단계. VGG 16 기반. )
- 1. convolution연산으로 local feature를 추출한다.
- 2. 배치 정규화를 이용해서 네트워크 안전성과 학습 속도를 높혀준다.
- 3. ReLU 활성화 함수로 비선형성을 추가한다.
- 4. max pooling으로 공간 해상도를 줄이고 주요 특징을 강조한다. 그리고 index를 저장.
- ex) 2 x 2 max pooling에서 가장 큰 값을 저장하고 해당 위치의 index를 기록
- 왜 index를 사용하나???
- 이미지의 해상도를 줄이는 과정에서 위치 정보가 손실된다... 그래서 이를 해결하기 위해서 max pooling 단계에서 선택된 위치의 index를 저장하고, decoder단계에서 이를 복원함.
- decoder 단계 ( encoder에서 추출된 특징을 사용해서 원본 해상도로 복원 및 각 픽셀의 클래스를 예측함.)
- 1. 업샘플링
- encoder에 저장된 max pooling의 index를 활용해서 원본 해상도로 복원함.
이렇게 하면, 불필요한 계산없이 정확한 복원이 가능하다.
- encoder에 저장된 max pooling의 index를 활용해서 원본 해상도로 복원함.
- 2. convolution 레이어
- 업샘플링한 결과를 convolution 연산으로 정제하여 픽셀간 연속성을 유지함.
- 3. softmax
- 각 픽셀의 클래스 확률 분포를 계산하여 분류를 수행한다.
- 1. 업샘플링
- encoder 단계 ( 입력 이미지에서 특징을 추출하기 위한 단계. VGG 16 기반. )
'코딩 및 기타 > 이미지' 카테고리의 다른 글
| 투영 변환 , 원근 투영의 수학적 모델 (1) | 2025.01.20 |
|---|---|
| coordinate system ( world , camera , pixel , normalized ) (0) | 2025.01.19 |
| VGG 16 (1) | 2025.01.17 |
| 허프 변환(Hough Transformation) (0) | 2025.01.17 |
| 모폴로지 Morphology (1) | 2025.01.16 |