From Goals, Waypoints & Paths To Long Term Human Trajectory Forecasting
[2012.01526] From Goals, Waypoints & Paths To Long Term Human Trajectory Forecasting
From Goals, Waypoints & Paths To Long Term Human Trajectory Forecasting
Human trajectory forecasting is an inherently multi-modal problem. Uncertainty in future trajectories stems from two sources: (a) sources that are known to the agent but unknown to the model, such as long term goals and (b)sources that are unknown to both
arxiv.org
Human-Path-Prediction/ynet at master · HarshayuGirase/Human-Path-Prediction · GitHub
Human-Path-Prediction/ynet at master · HarshayuGirase/Human-Path-Prediction
State-of-the-art methods for human trajectory forecasting. Contains code for papers published at ECCV 2020 and ICCV 2021. - HarshayuGirase/Human-Path-Prediction
github.com
1. multi-modal한 문제.
=> "하나의 그럴듯한 미래"만 존재하는게 아니라, "서로 다른 여러개의 그럴듯한 미래"가 동시에 존재한다는 것.
==> ex) 횡단보다 앞의 보행자 ==> (1.직진해서 건넘. / 2. 옆으로 비켜서 건넘. / 3. 잠시 멈춤. )==> 이 예시에는 3개의 그럴듯한 미래가 동시에 존재함.
2. agent
=> 움직이는 당사자
==> ex) 보행자 , 차량 , 로봇
3. model
=> agent의 미래를 예측하려는 알고리즘
4. epistemic
=> 지식의 부족에서 오는 불확실성
==> ex) 모델이 몰라서 생김(목적지) => 더 지식을 배우면 줄어듬... => 논문에서는 "목표의 multi-modality"로
5. aleatoric
=> 현상 자체의 우연성에서 오는 불확실성
==> 세상이 원래 랜덤해서 생김(군중과의 미세한 간섭 ) => 본질적으로 남음 => 논문에서는 "waypoints / 경로의 multi-modality"로 모델링
6. long prediction horizon
=> 예측 지평 : "미래를 몇 초까지 내다보느냐"를 뜻하는 시간 범위
==> 짧은 지평 : 보통 2~5초 앞
==> 긴 지평 : 훨씬 먼 미래까지... 논문에서는 최대 1분을 가르킴
7. scene 제약을 준수
=> scene(장면/지도)제약 : 환경의 지형 , 구조 , 규칙을 말한다.
==> ex) 보행자는 보도를 따라가며, 건물/잔디는 통과 못함.
==> ex) 차량은 차선/일반 통행을 지킨다. 인도를 올라가지 않음.
==> ex) 장애물이나 울타리는 통과 못함.
8. pixel-wise sigmoid
==> 출력 feature map의 각 픽셀마다, sigmoid함수를 독립적으로 적용해서 0~1사이의 값을 뽑는것.
====> pixel-wise : 공간 좌표 (i,j)의 각 픽셀에 대해서
====> sigmoid : 확률처럼 해석가능한 값으로 변환
0. Abstract
- 다중 에이전트의 인간 이동 경로 예측(human trajectory forecasting)은 본질적으로 multi-modal한 문제다.
- "미래 경로의 불확실성"은 두 가지 원천에서 비롯된다:
(a) agent에게는 알려져 있지만 model에는 알려지지 않은 원천(예: 장기 목표)
(b) agent와 model 모두에게 알려지지 않은 원천(예: 다른 에이전트의 의도와 의사결정에 내재한 제거 불가능한 무작위성).
- ==> 우리는 이 불확실성을 epistemic과 aleatoric의 두 원천으로 분해할 것을 제안한다.
- Epistemic 불확실성은 "장기 목표의 multi-modality"로,
aleatoric 불확실성은 "waypoints"와 "경로의 multi-modality"로 모델링한다.- ==> 이 이분법을 분명히 보여주기 위해,
우리는 또한 "최대 1분에 이르는 예측 지평"을 갖는 새로운 장기 trajectory forecasting 설정을 제안하는데,이는 기존 연구보다 최대 한 자릿수(≈10배) 더 길다.
- ==> 이 이분법을 분명히 보여주기 위해,
- 마지막으로 우리는 제안한 epistemic/aleatoric 구조를 활용해, 긴 예측 지평(long prediction horizon) 전반에 걸쳐 다양한 trajectory 예측을 생성하는, scene 제약을 준수하는(scene-compliant) trajectory forecasting 네트워크 Y-net을 제시한다.
- Y-net은 (a) Stanford Drone 데이터셋의 단기 예측 지평 설정에서 FDE 31.7% 향상, ETH/UCY 데이터셋에서 FDE 7.4% 향상을 포함해, 그리고 (b) 재구성한 Stanford Drone 및 Intersection Drone 데이터셋에서의 제안된 장기 예측 설정에서도, 이전 state-of-the-art 대비 성능을 크게 개선한다.
1. Introduction
- Sequence prediction은 신호처리, 패턴 인식, 제어공학 등 여러 공학 분야와, 시간적 측정값을 다루는 사실상 모든 도메인에서 근본적인 문제다.
- A. A. Markov [29]가 마르코프 체인으로 시 「예브게니 오네긴」에서 다음 음절을 예측한 고전적 연구부터,
현대의 autoregressive(자기회귀) 계열인 GPT-3 [6]에 이르기까지,
시퀀스에서 다음 요소를 예측하는 문제는 오랜 역사를 지닌다. - Time series forecasting은 시퀀스가 시간에 따라 샘플링된 요소들로 구성되는 설정에서 sequence prediction 문제의 핵심적인 구체화다.
- Autoregressive Moving Average Models(ARMA) [43]와 같은 여러 고전 기법들은,
현대의 state-of-the-art time series forecasting 방법들 [37]에서 deep learning 아키텍처 [41, 16]에 통합되어 왔다.- 그러나 인간은 무생물적 Newtonian entity, 즉 미리 정해진 물리 법칙과 힘에 종속된 존재가 아니다.
- 마찰과 물리 제약 하에서 당구대 위를 부드럽게 구르는 당구공의 향후 운동을 예측하는 문제는 인간의 움직임과 위치를 예측하는 문제와는 본질적으로 다르다.
- 인간은 공과 달리, 원하는 결과를 얻기 위해, 행동을 통해 의지를 행사하는 goal-conditioned agent다 [40].
- 그러나 인간은 무생물적 Newtonian entity, 즉 미리 정해진 물리 법칙과 힘에 종속된 존재가 아니다.
- 인간의 움직임을 예측하는 일은 다른 인간, 자율 로봇 [3], 자율주행차량 [39]과 같은 동적 에이전트에게 근본적으로 중요하다.
- 인간의 움직임은 본질적으로 goal-directed이며, 에이전트가 원하는 효과를 가져오기 위해 수행된다.
- 인간의 움직임은 본질적으로 goal-directed이며, 에이전트가 원하는 효과를 가져오기 위해 수행된다.
- 그렇지만, "에이전트의 과거 움직임"과 "포괄적인 장기 목표"에 조건을 걸었을 때에도, 미래 trajectory는 결정론적일까?
- ==> 붐비는 거리의 교차로에서 보행자 신호가 초록으로 바뀌기를 기다리고 있다고 생각해보자.
길을 건널 의도는 분명하지만, 정확한 미래 trajectory는 여전히 stochastic하다.- (1) 다른 보행자를 피하기 위해 방향을 틀 수도 있고,
(2) 신호가 곧 빨간불로 바뀌려 하면 보폭을 늘려 속도를 높일 수도 있으며,
(3) 무모한 자전거가 치고 나가면 갑자기 멈출 수도 있다.
- (1) 다른 보행자를 피하기 위해 방향을 틀 수도 있고,
- 따라서 과거에 관측된 움직임과 scene semantics에 조건을 걸더라도, 미래 인간의 움직임은 장기 목표와 같은 잠재적 의사결정 변수가 유발하는 epistemic uncertainty와, 환경 요인과 같은 무작위 의사결정 변수에서 비롯되는 aleatoric variability [10] 때문에 본질적으로 stochastic하다 [14].
- ==> 붐비는 거리의 교차로에서 보행자 신호가 초록으로 바뀌기를 기다리고 있다고 생각해보자.
- 이 이분법은 long-term forecasting에서 더욱 뚜렷한데, 미래에 대한 불확실성이 증가함에 따라,
aleatoric randomness가 short-term보다, "long-term horizon"에서 trajectory에 훨씬 더 강하게 영향을 미치기 때문이다. - 이는 인간 동역학 모델링에서 두 가지 stochasticity 요인을 함께 뒤섞기보다 계층적으로 모델링하는, factorized multimodal 접근을 동기부여한다.
- factorized multimodal ==> multi-modal의 원인을 2개의 층으로 분해(factorize).
1. 목표( 어디로 갈까? ) ---> epistemic 멀티모달
2. 경로/경유점( 어떻게 갈까? ) ----> aleatoric 멀티모달
- factorized multimodal ==> multi-modal의 원인을 2개의 층으로 분해(factorize).
- 우리는 에이전트의 장기 잠재 목표가 motion prediction 내의 epistemic uncertainty를 나타낸다고 가정한다.
- 에이전트는 trajectory를 계획·수행할 때 마음속에 목표를 갖지만, 예측 시스템에는 그것이 알려져 있지 않다.
- ==> 물리적 관점에서 이는 에이전트가 “어디로 가고 싶은가”에 해당한다.
- 반면 aleatoric uncertainty는 그 목표로 이어지는 경로의 stochasticity로 표현되며,
"다른 에이전트 같은 환경 변수", "에이전트가 사용할 수 있는 부분적 scene 정보" , 그리고 무엇보다 인간 의사결정에 존재하는 "무의식적 randomness [18]" 등을 포함한다.- ==> 물리적 관점에서 이는 에이전트가 “어떻게 그 목표에 도달하는가”에 해당한다.
- 에이전트는 trajectory를 계획·수행할 때 마음속에 목표를 갖지만, 예측 시스템에는 그것이 알려져 있지 않다.
- 따라서 우리는 먼저 epistemic uncertainty를 모델링한 뒤, 그 추정치에 조건을 걸어 aleatoric stochasticity를 모델링할 것을 제안한다.
- 구체적으로, RGB scene과 과거 motion history가 주어졌을 때, 우리는 먼저 에이전트의 장기 목표에 대한 확률분포를 명시적으로 추정한다.
==> 이는 예측 시스템 내의 epistemic uncertainty를 나타낸다.
- 구체적으로, RGB scene과 과거 motion history가 주어졌을 때, 우리는 먼저 에이전트의 장기 목표에 대한 확률분포를 명시적으로 추정한다.
- 또한 일부 선택된 미래 waypoint 위치들에 대한 분포를 함께 추정하고, 이를 샘플링된 goal point와 결합해 나머지 중간 trajectory 위치 전반에 대한 명시적 probability map을 얻는다.
- 이는 예측 시스템 내의 aleatoric uncertainty를 나타낸다.
- ===> 함께 사용했을 때, "epistemic goal 분포"와 "aleatoric waypoint·trajectory 분포"에서의 샘플들이 결합되어, 예측된 미래 trajectory를 형성한다.
- 이는 예측 시스템 내의 aleatoric uncertainty를 나타낸다.
- 요약하면, 우리의 기여는 세 가지다.
1. 이전 문헌보다 약 한 자릿수(≈10배) 더 긴, 최대 1분 미래까지 확장된 새로운 long-term prediction 설정을 제안한다.
2. scene semantics를 효과적으로 활용하면서, goal과 path의 multi-modality를 명시적으로 모델링하는 scene-compliant long-term trajectory prediction network, Y-net을 제안한다.
3. factorized multimodality 모델링이 제안한 long-term 설정과 잘 연구된 short-term 설정 모두에서 Y-net이 state-of-the-art를 향상시킴을 보인다. - 우리는 단기 설정에서 Stanford Drone [32] 및 ETH [31]/UCY [23] 벤치마크에 대해 Y-net의 성능을 벤치마크했다.
- 그 결과, SDD에서 ADE 13.0%, **FDE 31.7%**의 유의미한 개선을 보였고, ETH/UCY에서는 ADE가 동급(par)이며 FDE 7.4% 개선을 달성했다.
- 더 나아가 제안한 long-term 설정에서 Stanford Drone과 Intersection Drone Dataset [5]에 대해 Y-net의 성능을 분석했으며, 기존 단기 방법 대비 ADE 50.7%+ / 39.7%+, **FDE 77.1% / 56.0%**의 상당한 향상을 보였다.

Figure 1: 저자는 장기(long-term) 인간 trajectory forecasting 문제를 다룬다.
➀ 지난 5초 동안의 장면에서, 한 에이전트의 "과거 움직임(파란색)"이 주어졌을 때, 다음 1분 간의 멀티모달 미래 움직임을 예측하는 것이 목표다 .
➁ 이를 위해, 전체 multi-modality를 "epistemic 요인"과 "aleatoric 요인"으로 "분해(factorize)"할 것을 제안한다. ( 과거 궤적(파란점)이 주어졌울때, 앞으로 1분의 "여러 가능한 미래"를 예측
➂ Epistemic 요인은 "장기 목표(long-term goals)"에 대한 추정 분포로 모델링하고 ,
➃ Aleatoric 요인은 각 목표마다 중간 경유점(intermediate waypoints) 과trajectory 에 대한 분포로 모델링한다.
➄ 이 과정은 여러 목표와 경유점에 대해 반복되어, scene-compliant한 멀티모달 인간 trajectory forecasting을 이룬다 .
==> 각 색은 서로 다른 샘플된 목표에 대해 예측된 trajectory를 나타낸다.
==> 파란점은 "관측된 과거 5초 움직임"
==> 색 히트맵은 확률이 높을수록 밝다.
==> ⭐: 샘플된 목표(goal)
==> ◆: 샘플된 경유점(waypoint)
==> 점선 궤적(색별): 샘플된 미래 trajectory(목표별로 색이 다름)
2. Related Works
- 최근 여러 연구가 다양한 설정에서 human trajectory prediction을 조사해왔다.
- 넓게 보면, 이러한 접근들은
(i) forecasting에서의 multimodality를 어떻게 정식화했는지,
(ii) 예측 모델에 제공되는 "입력 신호",
(iii) 모델이 산출하는 예측 결과의 "성격"과 "형태"에 따라 분류할 수 있다.
- 사용된 "입력 신호"는 에이전트의 past motion history , human pose , RGB scene image, scene semantic cues , location , 다른 보행자의 gaze , 장면 내 moving vehicles(예: 자동차) , 그리고 에이전트의 goals [28]처럼 latent하게 추론된 신호 등 다양하다.
- 산출되는 예측 결과의 형태 또한 다양하며, 특히 "multi-modality"와 "scene-compliant forecasting"이 선행 연구의 핵심 주제로 자리 잡고 있다.
- ( scene - compliant forecasting : 예측된 궤적이 "장면의 의미론(semantic map)"과 "물리적 제약"을 위배하지 않도록 만드는 예측방식)
2.1 Unimodal Forecasting
- 초기 trajectory forecasting 연구는 unimodal한 미래 예측에 집중했다. ( unimodal 단봉성 )
- Social Forces [15]는 상호작용을 인력/척력으로 모델링하고, 미래 trajectory를 이러한 힘 아래에서 진화하는 deterministic path로 본다.
- Social LSTM [1]은 장면 내 다른 에이전트에 주목하여, 그 영향력을 pooling 모듈로 모델링한다.
- [46]은 ego-centric view에서의 motion을 예측하며, body pose와 gaze, 그리고 camera wearer의 ego-motion을 활용해 다른 에이전트의 미래 위치를 예측한다.
- [42]는 attention을 사용해 타깃 에이전트의 타 에이전트와의 상호작용을 모델링한다.
- [27]은 pose prediction을 위한 ‘global’ 브랜치로 trajectory를 예측하고, 이후의 다운스트림 태스크(예: pose prediction)를 이 predicted unimodal trajectories에 condition하도록 제안한다.
2.2 Multimodality through Generative Modeling
- 다른 연구 흐름은 future prediction에 내재한 stochasticity를, 사전분포(prior)가 정의된 latent variable을 통해 모델링한다. ==> (예: conditional variational auto-encoders, CVAE [20]).
- DESIRE [22]는 inverse reinforcement learning 기반 접근으로, latent variable 샘플링을 통해 multimodality를 도입하고, 이를 ranking 및 refinement module로 최적화한다.
- [27]은 CVAE를 사용해, 과거 motion history에 condition된 보행자의 final position의 multimodality를 포착한다.
- Trajectron++ [36]은 에이전트의 trajectory를 graph-structured recurrent network로 표현하여, 다양한 에이전트와의 상호작용을 고려한 scene-compliant trajectory forecasting을 수행한다.
- LB-EBM [30]은 latent space에서 energy-based model을 학습하고, policy generator로 latent vector를 trajectory로 사상한다.
- AgentFormer [47]는 attention 기반 방법으로, sequence representation을 통해 시간 차원과 사회적 상호작용을 jointly 모델링하면서 각 에이전트의 identity를 보존한다.
- Introvert [38]는 관측된 trajectory에 condition된 3D visual attention 메커니즘을 사용해, 비디오에서 scene 및 social information을 추출한다.
- 이 접근은 future displacement distribution을 예측하고, 여러 개의 시퀀스를 샘플링할 수 있다.
- ( future displacement distribution : 현재 위치 or 마지막 관측 시점을 기준으로, 미래에 얼마나 or 어느 방향으로 이동할지(Δx, Δy)의 확률분포다..
- 또 다른 흐름인 Social GAN [13]은 adversarial losses [12]를 사용해 예측 내 multimodality를 도입한다.
- 이러한 generative 접근은 다양한 trajectory를 생성하지만, "중요 모드(critical modes)"의 전반적 coverage를 보장하기 어렵고, 예측 trajectory의 방향, 샘플 수 등의 속성에 대한 제어력이 제한적이라는 한계가 있다.
- 반면, 우리가 제안하는 Y-net은 "explicit probability maps"를 추정하므로, 후속 태스크(downstream task)에서 spatial constraints를 쉽게 통합할 수 있다.
- explicit probability maps : 공간을 grid로 나눠서, 각 pixel이 "정답 위치일 확률"을 직접 출력한 히트맵.
즉, 모델이 좌표 한 점을 뱉는 게 아니라, 장면 위 모든 위치에 대한 확률 분포를 명시적으로(explicit) 내놓음
- explicit probability maps : 공간을 grid로 나눠서, 각 pixel이 "정답 위치일 확률"을 직접 출력한 히트맵.
2.3 Multimodality through Spatial Probability Estimates
- 또 다른 연구 흐름은 "확률 맵(probability maps)"을 추정해 multimodality를 획득한다.
- Kitani et al. [21]의 Activity Forecasting은 hidden Markov Decision process를 사용해 미래 경로를 모델링한다.
- 다만 [21]의 미래 예측은 ‘approach car’, ‘depart car’ 같은 activity labels에 condition된다는 점이 우리 연구와 다르다.
- 보다 최근에는, grid-based scene representation을 사용해 미래 시점들에 대한 확률을 추정하는 연구들이 제안되었다 [25, 26, 9].
- 이와 관련하여 [27, 48, 8]과 같은 일부 선행 연구는 goal-conditioned trajectory forecasting 방법을 제안한다.
- Kitani et al. [21]의 Activity Forecasting은 hidden Markov Decision process를 사용해 미래 경로를 모델링한다.
- 그러나 *"epistemic uncertainty(또는 goals)"와 "aleatoric uncertainty(또는 paths)"를 "factorized 방식"으로 모델링하는 접근은, 우리가 제안하는 Y-net 이전에는 보고되지 않았다.
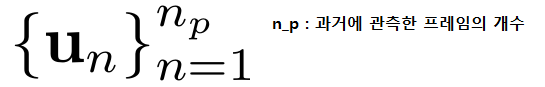


- 1. 입력과 전처리
- 1-a. RGB Image ==> Segmentation Map
- RGB 이미지를 semantic segmentation network( U-net 계열 )로 처리해서, "장면의 클래스 맵 S"를 만든다.
- 0. input은 RGB이미지 H*W*3
1. [도로, 보도, 잔디, 계단, 벽]이 있다고 가정.....
2. 이러면 한번의 처리를 거쳐서 출력을 얻음.
==>출력은 H*W*5의 도로/보도/잔디/계단/벽 각각의 확률맵을 얻음. ( 이러면 s=5 )
- 0. input은 RGB이미지 H*W*3
- RGB 이미지를 semantic segmentation network( U-net 계열 )로 처리해서, "장면의 클래스 맵 S"를 만든다.
- 1-b. Past Trajectory ==> Trajectory Heatmaps
- 관측된 각 timestep마다 하나씩, agent 위치를 중심으로 한 heatmap채널을 쌓아서, nₚ 채널짜리 "텐서 H"
를 만든다.
- 관측된 각 timestep마다 하나씩, agent 위치를 중심으로 한 heatmap채널을 쌓아서, nₚ 채널짜리 "텐서 H"
- 1-c. Concatenate(⊕)
- S와 H를 channel방향으로 붙여, H_s ∈ R^( H x W x ( C + nₚ ) )를 만들고, 이것을 encoder의 입력으로 사용. ( "s의 총개수"가 C다. )
- 1-a. RGB Image ==> Segmentation Map
- 2. encoder U_e ( 공통적인 backbone)
- 여러 개의 { conv + ReLU ==> Max-pool }을 사용해서 해상도를 절반씩 줄인다.
이러한 과정으로 깊고 컴팩트한 특징인 Hₘ 을 만든다. - 각 단계의 중간 특징인, Hₘ 은 스킵 연결로 "2개의 decoder"에 전달된다.
- 가장 마지막은 H_M이고, 이는 가장 작고 체널이 가장 깊다
- 스킵연결 : 회색 점선 박스/화살표
- skip connection이란? ==> 초기층의 출력을 뒤쪽 층으로 "건너뛰어" 직접 전달하는 연결을 의미.
- output은 가장 오른쪽
- ==> U-Net 처럼 여러 block을 거치며, "해상도는 절반씩 감소" 및 "채널은 증가"......
- 여러 개의 { conv + ReLU ==> Max-pool }을 사용해서 해상도를 절반씩 줄인다.
- 3. 상단의 decoder U_g ( Goal & waypoint )
- input : encoder의 최종적인 H_M이다. 그리고 각 단계에서 대응하는 Hₘ을 skip으로 병합.
- 연산 과정 ( 확대 및 복원 )
- 노란색 블럭 "Upsampling + Conv " , 청색 블럭 "Conv + ReLU"이 번걸아가며, 해상도를 2배씩 upsample한다.
- 매번의 upsample 뒤에, 대응되는 해상도의 Hₘ과 skip merge
- ( H_M만 쓴다면, 작은 해상도 때문에 세밀한 goal/waypoint detail이 사라지니, skip merge가 필수다. )
==>그니까 H_M은 U_e의 결과물이고, 이것만으로 업샘플링하면 세밀한 표현이 감소하니, skip merge가 필수라는 말 )
- ( H_M만 쓴다면, 작은 해상도 때문에 세밀한 goal/waypoint detail이 사라지니, skip merge가 필수다. )
- 출력
- "짙은 파랑"으로 마무리해서, pixel별 확률맵을 만듬
- 픽셀변 확률맵 ==> H * W * C이다. C는 채널수다. 각 채널 c는 하나의 타켓( goal or 특정 waypoint )에 대응한다. ==> 각 픽셀값은 "그 채널의 타켓이 해당 픽셀에 존재할 확률"로 해석한다.
- 위에서 중요한건 sigmoid이니, pixel 간 합이 1이 되도록 정규화하지 않는다...
즉, 하나의 채널안에서도 여러 pixel이 동시에 높은 값을 가질수있다.
학습은 보통 BCE( with logits )로 픽셀별로 진행한다. - 좌표가 필요할때는, 해당 확률맵에서 argmax or softmax로 (x,y)를 뽑아낸다.
- 위에서 중요한건 sigmoid이니, pixel 간 합이 1이 되도록 정규화하지 않는다...
- 채널 크기 : H * W * ( N^w + 1 ) ....여기서 N^w는 예측에 사용할 waypoint의 개수이다.
- 즉, waypoint용 맵 N^w장 + goal용 맵 1장을 동시에 뽑는다.
- 샘플링 및 조건화 ( 그림의 주사위 아이콘 )
- 픽셀별 확률맵에서 "non-parametric sampling"으로 "좌표 샘플"을 얻음.
- 얻은 "좌표 샘플"을 가지고, Gaussian heatmap으로 렌더링한 것이, 그림의 "Goal & waypoint heatmap"이다.
- 위의 "heatmap"은 "encoder U_t"에 "조건(conditioning)"으로 전달되어, "어떤 goal/waypoint를 향할 것인가"라는 것을 명시적으로 주입.
- 4. 하단 인코더 U_t ( 전체 future trajectory 분포 (시간축 전재 ) )
- 입력 : encoder의 skip시킨 정보 Hₘ , U_g에서 얻은 Goal/Waypoint Heatmap(조건).
- 또한, Sence S , Past heatmaps H의 정보는 이미 Uₑ의 경로를 통해 내재되어 있으며, U_g의 샘플 결과가 추가적인 context로 들어옴.
- 연산
- U-Net 스타일.
- 출력
- 각 미래 시점 t=1 , ... , n_f에 대해서, 픽셀별 "위치 확률 분포"를 예측.
- 채널의 크기 : H * W * n_f
- ==> 각 채널이 "그 시점의 위치 분포"이다.
- 그림의 "future trajectory distribution"(파란색 맵 스택)으로 나타남.
- 입력 : encoder의 skip시킨 정보 Hₘ , U_g에서 얻은 Goal/Waypoint Heatmap(조건).
==> 학습 신호가 붙는 위치...( 그림에는 없지만 ...)
====> U_g 출력의 goal/waypoint 분포에 BCE loss( L_goal , L_waypoint )
====> U_t 출력의 시점별 trajectory 분포에 BCE loss( L_trajectory )
====> GT는 관측 위치를 중심으로 한 Gaussian heatmap
======> 총 손실 L = L_goal + 로 end-to-end 공동 학습.
3. Proposed Method
- multi-modal trajectory prediction problem은 아래처럼 정의할 수 있다...
- 1. RGB scene image I가 주어진다.
- 2. 장면 I안에 "보행자의 과거위치(식 A)"가 주어진다.
- 3. 지나간 시간은 " t_p = nₚ / FPS "초이다.
- t_p ==> past time horizon
- nₚ ==> 그 과거 구간에 포함된 timestmap갯수. ( 과거에 관측한 프레임의 개수 )
- FPS ==> 샘플링 주파수 ( 초 당 프레임 수 )
- 과거에 관측한 프레임이 20이고, 10fps라면, 2초가 지난것
- 4. 모델의 목적은 "미래 t_f초 동안의 보행자 위치(식B)"를 예측하는것이다.
- t_f = n_f / FPS
- n_f ==> 미레의 프레임 수
- u_n^i 는 "n번째 시점의 보행자 i의 위치".
- ==> 미래는 stochastic하므로, 모델은 여러 개의 미래 trajectory 예측을 생성한다.
- 본 연구에서는 전체 stochasticity를 두 가지 모드로 factorize한다.
- 1. epistemic uncertainty에 해당하는 모드, 즉 최종 목적지(final destination)의 multy-modality이다.
- 해당 모듈은 K_e개의 goal을 산출한다.
- 2. aleatoric uncertainty에 해당하는 모드, 즉 주어진 goal 하에서 통제 불가능한 랜덤성으로부터 비롯되는 목적지까지 가는 경로(path)의 multy-modality이다.
- 해당 모듈은 "추정된 각각의 goal"마다 K_a개의 예측을 생성한다.
- 1. epistemic uncertainty에 해당하는 모드, 즉 최종 목적지(final destination)의 multy-modality이다.
- "짧은 시간 지평(short temporal horizon)"에서는 "전체 경로 길이"가 짧기 때문에,
하나의 goal에 대해 가능한 경로 선택지가 제한적이고 서로 유사하다.- 이는 자연스럽게 K_a = 로 모델링되며, 따라서 예측되는 경로의 총 개수(기존 연구에서의 K)는 이 짧은 지평 설정에서는 K_e와 동일해진다.
- 반면 "긴 시간 지평(longer temporal horizons)"에서는 같은 goal로 가는 경로가 여러 개 존재하므로 K_a > 1이 된다.
- 이제 제안 모델 Y-net의 작동 방식과 3개의 sub-network U_e , U_g , U_t를 상세히 설명한다.
그리고 비모수(non-parametric) 샘플링 과정(Section 3.2)과 사용된 loss functions를 기술한다.
3.1. Y-net Sub-Networks
- scene 정보를 "semantic space(이미지와 유사한 표현)"에서, 궤적 정보를 "coordinates(좌표)"로 함께 효과적으로 사용하려면, 서로 다른 모달리티 사이에 "pixel-wise alignment(픽셀 단위 정렬)"가 필요하다.
- semantic space ==> "이미지처럼 생긴 2D 격자 공간( H x W ) "이다. 이는 픽셀 격자이지만, 각각의 채널들이 의미를 담는다. ( ex. 보도/차도/잔디/건물/차선 등 ) , ( height x width x channels )
- 몇몇 선행 연구 [35]는 RGB 이미지 를 pretrained CNN에서 뽑은 hidden state vector로 인코딩하여 이를 달성한다.
- 이렇게 하면 네트워크가 scene 정보를 갖게 되긴 하지만, 이 벡터로 flatten하는 과정에서 의미 있는 **spatial signal(공간 신호)**이 심하게 뒤섞이고 pixel alignment가 파괴된다.
- [28]에서 scene 정보 없이도 이전 state-of-the-art를 달성한 것으로 부각되며, 선행 연구들에서 이미지 정보를 오용했음을 시사한다.
- 이에 우리는 trajectory-on-scene heatmap 표현을 채택한다.
- 즉, trajectory를 이미지 I와 동일한 공간(격자/픽셀)에서 표현함으로써 alignment 문제를 해결한다.
==> scene에 대한 표현은 rgb이미지(선택적)와 "여러 도보/차선/잔디"등을 의미 채널을 채널 축으로 쌓는것이다.
====> 이를, "H×W×C 텐서(semantic map)"로 표현한다.
==> 텐서가 정의된 "픽셀 좌표계(H×W)"를 semantic space라고 부른다
3.1.1 Trajectory-on-Scene Heatmap Representation
- RGB image I는 우선 U-net과 같은 semantic segmentation network를 거친다.
그리고 surface가 제공하는 affordance( ex.걷기,서있기 달리기 등 )에 따라서 C개의 class로 구성된 segmentation map S를 생성한다. - 한편, 과거 motion history( 식A )는 trajectory heatmap H로 변환된다.
- 이 heatmap은 image I와 동일한 spatial size를 가진다. 그리고 time-step마다 하나의 channel을 가지니, 총 nₚ 개의 channel이 된다.
- 수식은 아래와 같다. ( 식 1 )
- 즉, 특정 time-step에서의 agent 위치 u_n과 픽셀 좌표 (i,j)간 거리를 정규화하여 heatmap 값을 계산한다.
- H( n , i , j )에서 n은 과거 시점 index , i와 j는 이미지 좌표.. ==> 즉, n번째 과거 위치에 대한 heatmap의 (i,j)픽셀 값
- max(x,y)..... 즉, 분모는 이미지 전체 영역 I에서 u_n과의 가장 먼 거리이다. 즉, 정규화 상수다.(이미지 한쪽 구석에서 u_n까지의 거리 같은게 최대값)
- 앞의 2의 배수는 값의 범위를 조절하는 스케일링 팩터. 이로 인해서 전체 이미지를 [0,2] 범위로 정규화함.
- 즉, 특정 time-step에서의 agent 위치 u_n과 픽셀 좌표 (i,j)간 거리를 정규화하여 heatmap 값을 계산한다.
- 수식은 아래와 같다. ( 식 1 )

- 이 trajectory heatmap 표현은 "semantic map 와 channel 방향으로 concatenate되어,
trajectory-on-scene heatmap tensor H_S를 만든다.- 이 텐서는 H×W×(C+ nₚ ) 차원을 가지며, encoder network U_e의 입력으로 사용된다.
3.1.2 Trajectory-on-Scene Heatmap Encoder Uₑ
- Tensor H_s는 "encoder Uₑ"에 의해서 처리된다.
- 이는 U-Net encoder구조를 기반으로 설계된다. ( fig 2참고 )
- "encoder Uₑ"는 M blocks로 구성되며, 각 block마다 "spatial dimension"이 max-pooling( stride=2 )에 의해서 절반으로 줄어든다.
- M blocks ==> 인코더/디코더를 몇 단계(level)로 쌓았는지를 말함. ( 논문에서는 5로 설정 )
- 동시에 channel depth는 "C + nₚ" 에서 시작해, { convolution + ReLU layer }를 거치며 점차 증가하여, 일정 block 이후에는 약 두 배씩 확장된다.
- 최종적으로, M-th block에서 얻어진 spatially compact한 feature representation과, 중간 block에서 생성된 "Hₘ (1 ≤ m ≤ M)"들이 저장된다.
- 이 feature들은 이후 "goal decoder U_g"와 "trajectory decoder Uₜ"로 전달된다.
3.1.3 Goal and Waypoint Heatmap Decoder U_g
- 다양한 spatial resolution을 가진 "trajectory-on-scene tensor 은 goal 및 waypoint heatmap decoder인 U_g로 전달된다.
- U_g는 U-net 구조 [34]의 expansion arm을 기반으로 한다.
- expansion arm : U-net에서 해상도를 복원하는 decoder경로.
- expansion arm : U-net에서 해상도를 복원하는 decoder경로.
- 중앙 block은 "두 개의 {convolutional layer + ReLU }"로 구성되며, 최종적으로 압축된 feature tensor Hₘ 을 입력으로 받는다.
- Expansion arm은 "bilinear up-sampling"과 "convolution"을 결합한 Deconvolution [34]을 통해 각 block의 해상도를 두 배로 확장한다. ( 그림2의 주황색 블록 )
- Expansion arm은 "bilinear up-sampling"과 "convolution"을 결합한 Deconvolution [34]을 통해 각 block의 해상도를 두 배로 확장한다. ( 그림2의 주황색 블록 )
- 각각의 Deconvolution 후에는 "encoder Uₑ"의 중간 표현 Hₘ 이 skip connection을 통해 병합되며,
두 개의 convolutional layer(ReLU 포함)로 처리된다.- ==> 이러한 중간 고해상도 feature map을 결합하는 것은 중요하다.
- ==> 왜냐하면 최종 feature Hₘ 만 사용할 경우 goal heatmap의 해상도가 제한되어, 중간 feature map에 존재하는 세밀한 공간 정보를 잃기 때문이다.
- ==> 왜냐하면 최종 feature Hₘ 만 사용할 경우 goal heatmap의 해상도가 제한되어, 중간 feature map에 존재하는 세밀한 공간 정보를 잃기 때문이다.
- ==> 이러한 중간 고해상도 feature map을 결합하는 것은 중요하다.
- U-net block은 "Deconvolution", "feature merging" , "두 개의 convolutional layer"로 구성되며, 이 과정이 총 번 반복된다.

- (pixel-wise sigmoid의 결과는 H*W*C heatmap의 모든 요소가 0~1 범위로 나온다.)


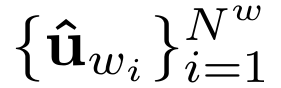
3.1.4 Trajectory Heatmap Decoder U_t
- U_t는 개의 decoder block으로 구성되며, 이는 U_g와 유사하게 동작한다(Section 3.1.3).
- 그러나 차이점은 U_t는 scene map , 과거 trajectory(식A)뿐 아니라, 샘플링된 goal과 waypoint에도 조건화된다는 점이다.
- U_g가 산출한 확률 분포는 "potential goal"과 "waypoint set"을 샘플링하는 데 사용된다.
- 이 샘플링 과정은 Section 3.2와 Supplementary Section 1에서 자세히 설명된다.
- 총 K_e개의 goal이 샘플링되고( Epistemic 과정), 각 goal에 대해 K_a개의 path가 샘플링된다( aleatoric 과정).
- "샘플링된 goal(식 D)"과 "waypoint 집합(식 E)"은 Section 3.1.1에서 설명한 방식과 동일하게 "heatmap representation H_g"로 변환된다.
- 이후 이 "tensor H_g"는 각 block의 spatial size에 맞게 downsample되고,( downsample된는건 goal&waypoint heatmap이다.)
대응되는 encoder의 중간 표현 Hₘ 과 결합된다. - 결합된 출력은 이전 U_t block의 출력과 함께 다음 block으로 전달된다.
- 각 미래 timestep마다 개별적인 확률 분포가 예측된다.
- 따라서 최종 출력의 크기는 " H * W * n_f이며, 각 channel은 해당 timestep에서의 위치 분포를 나타낸다.
3.2 Non-parametric Distribution Sampling
- 미래 프레임 위치의 확률 분포 P가 주어졌다고 하자.
- 이는 확률 행렬 X로 표현된다.
- 우리의 목표는 이 확률 분포로부터, "agent의 위치에 대한 추정값"을 2차원 좌표로 샘플링하는 것이다.
- 그러나 실제 학습 과정 초기에 P는 매우 noisy하기 때문에, 단순한 argmax를 사용하는 것은 안정적이지 못하다.
- 따라서 본 연구에서는 softargmax 연산 [11]을 사용하여 가장 가능성이 높은 위치를 더 견고하게 근사한다.

- 즉, 확률 분포의 가중 평균을 사용하여 위치를 계산함으로써, 초기 단계에서도 안정적으로 좌표를 추정할 수 있다.
- 추가적으로, Test-Time Sampling Trick과 Conditional Waypoint Sampling 같은 세부적인 샘플링 기법은 Supplementary Section 1.1 및 1.2에 기술되어 있다.
3.3 Loss Function
- 모델의 출력은 timestep별 확률 분포이므로, 우리는 샘플링된 좌표가 아니라 추정된 확률 분포 P^에 직접 loss를 부여한다.
- Ground truth는 관측된 위치를 중심으로 하고, 미리 정해진 분산 를 갖는 Gaussian heatmap P으로 표현된다.
- 세 네트워크 U_e , U_g , U_는 end-to-end로 공동 학습되며,
goal, waypoint, trajectory 분포에 대한 binary cross entropy loss의 가중 합을 최적화한다.

4. Results
- 본 연구는 Y-net의 성능을 평가하기 위해 세 개의 데이터셋을 사용한다:
1. Stanford Drone Dataset (SDD) [33],
2. Intersection Drone Dataset (InD) [5],
3. ETH/UCY [31, 23] forecasting benchmark.
4.0.1 Stanford Drone Dataset
- 제안 모델은 널리 사용되는 Stanford Drone Dataset [33]에서 벤치마크된다.
- 이 데이터셋은 최근 몇 년 사이 여러 방법들이 state-of-the-art를 크게 끌어올린 바 있다 [45].
- 데이터셋은 스탠퍼드 대학 캠퍼스에서 드론의 bird’s-eye view로 촬영된 20개 탑다운 장면에 걸쳐 11,000명 이상의 고유 보행자를 포함한다.
- 단기 예측 설정(short term): 선행 연구 [35, 28]의 표준 설정/분할을 따른다.
샘플링은 FPS = 2.5로 수행하며, 입력 길이 n_p=8, 출력 길이 n_f=12이다.
즉, t_p = n_p / FPS = 3.2 s ,
t_f = n_f / FPS = 4.8 s
- 단기 예측 설정(short term): 선행 연구 [35, 28]의 표준 설정/분할을 따른다.
- 본 연구의 장기 예측 설정(long term): FPS = 1로 샘플링한다.
이에 따라 n_p = 5 (과거 5초)를 입력으로 사용하고 최대 1분 앞까지 예측한다. - 장면에는 semantic segmentation map을 부여하며,
C=5개의 “stuff” 클래스(문헌 [7])—pavement, terrain, structure, tree, road—를 사용한다.- 이 클래스들은 표면의 walking affordability에 기반한다.
- 데이터셋 분할은 단기 설정과 동일하게 하여, 학습 중 보지 못한 장면에 대한 성능을 평가한다.
4.0.2 Intersection Drone Dataset (InD)
장기 trajectory forecasting 벤치마크를 위해 Intersection Drone Dataset [5]을 사용한다.
이 데이터셋은 도시 환경의 4개 교차로에서 10시간 이상 측정된 데이터를 포함한다. 원본은 FPS = 25로 기록되었다.
- 장기 SDD 설정과 맞추기 위해 궤적을 FPS = 1로 다운샘플한다.
- 보행자가 아닌 트랙과 짧은 궤적을 필터링하고, 겹침 없는(sliding window, no overlap) 방식으로 긴 궤적을 분할한다.
- 전처리 후 InD는 n_p=5 , n_f=30을 갖는 1,396개 장기 궤적을 포함한다.
- unseen environment에서의 성능을 평가하기 위해, 테스트에서는 location ID 4만 사용한다.
- 장면 라벨링은 SDD와 동일하게 C=5 클래스를 사용한다.
- 저자들이 제공한 scale factor로 world coordinates → pixel coordinates 변환을 수행하고, 평가지표는 픽셀 단위로 계산한다
4.0.3 ETH & UCY
ETH/UCY 벤치마크는 최근 몇 년간 단기 예측 설정에서 널리 사용되어 왔으며 [44], 지난 2년 내에 평균 **~64%**의 성능 향상이 보고되었다 [13].
다섯 개의 상이한 장면으로 구성되며, 좌표는 world coordinates(미터) 로 제공된다.
검증은 선행연구 [35, 13, 9]와 동일하게 leave-one-out 전략을 따른다.
- 이들 데이터셋은 표면이 제공하는 affordance의 클래스 종류가 적으므로, C=2 (각 픽셀을 ‘road’ 혹은 **‘not road’**로 구분)만 사용한다.
- 프레임 샘플링은 단기 SDD와 동일하게 FPS = 2.5, nf=12 (미래 4.8초)이며, 입력은 np=8 (과거 3.2초)이다.
4.0.4 Implementation Details
- 전체 네트워크는 Adam optimizer [19]로 learning rate 0.0001, batch size 8 설정에서 end-to-end 학습한다.
- Pre-trained segmentation 모델을 사용하며, 각 데이터셋에 대해 finetuning한다.
- 추가 세부사항은 supplementary materials에 기술되어 있다
4.0.5 Metrics
성능 평가는 표준 지표인 ADE (Average Displacement Error) 및 FDE (Final Displacement Error) 를 사용한다.
- ADE: 예측된 미래 전 시점에 대해, 예측 위치와 GT 위치 간의 ℓ_2오차의 평균.
- FDE: 최종 시점의 예측 위치와 GT 위치 간 ℓ_2 오차.
- 다중 미래를 출력하는 경우(샘플을 여러 개 생성), 선행 연구 [13]를 따라 모든 예측 중 최솟값(min error) 을 보고한다.
- ADE/FDE는 결정론적(deterministic) 평가에는 적합하지만, 예측 분포 대신 샘플에 의존한다는 한계가 있다.
- 따라서 [17, 36]과 동일한 방식으로 KDE-NLL (kernel density estimate-based negative log-likelihood) 도 함께 보고한다.
- 표준화된 KDE를 사용해 각 미래 시점의 확률분포함수를 추정하고, 그 분포에 대해 GT trajectory의 NLL을 계산한다.
- Y-net은 explicit probability maps를 예측하므로, 선행 문헌과의 일관성과 공정한 비교를 위해 KDE를 적용한다.
4.1. Short Term Forecasting Results
4.1.1 Stanford Drone Results
- Table 1은 SDD의 단기 예측 설정 결과를 제시한다.
- 저자들은 K_e=5와 K_e=20두 경우를 보고한다.( epistemic )
- 단기 설정에서는 aleatoric multi-modality가 제한적이므로 Ka=1로 두어,
과거 연구들이 평가에 사용한 20개 trajectory 샘플과 공정하게 비교 가능하게 한다. - **Ke=20K_e=20**에서 제안 모델의 성능은 ADE 7.85, FDE 11.85로, 이전 SOTA인 LB-EBM [30] 대비 ADE 13.0%, FDE 31.7% 향상.
- **Ke=5K_e=5**에서도 ADE 11.49, FDE 20.23을 달성하여, 이전 SOTA **TNT [48]**보다 우수.
4.1.2 ETH/UCY Results.
Table 2에 ETH/UCY 벤치마크 결과를 보고한다. SDD와 동일하게 Ke=20, Ka=1K_e=20,\ K_a=1을 사용했다. Y-net은 AgentFormer [47] 대비 FDE를 7.4% 개선하여 0.27을 달성했고, ADE는 0.18로 동급 수준을 보였다.
(ETH/UCY는 world 좌표계(미터) 기준, SDD는 픽셀 기준으로 평가됨.)