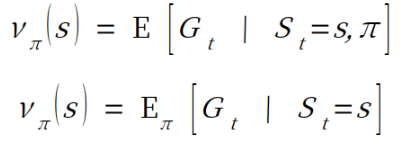 이는 상태 가치 함수이다.
이는 상태 가치 함수이다.
행동 가치 함수란? action - value function
- 상태 가치 함수에서 필요한 것은 상태 s와 정책π 이다.
여기에서 행동 a를 추가한것이 행동 가치 함수이다.
Q함수라고도 한다.

- 시간이 t일때, state=s인 경우에 action=a를 수행함을 의미하며, t+1부터는 정책π에 따라서 행동을 한다.
이때 얻을 수 있는 기대 수익은 qπ( s,a ) 이다.
- 상태 가치함수와 다른점은, 상태 가치 함수는 정책π에 따라서 action을 수행한다면, 행동 가치 함수에서는 action을 자유롭게 선택한다.
- 만약 Q함수의 action을 정책에 따라서 선택하게 한다면, 상태 가치 함수와 같아진다.
 행동 후보에 따른 기대 수익 밑 Q함수의 가중치 합
행동 후보에 따른 기대 수익 밑 Q함수의 가중치 합
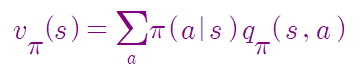 위의 과정에 따라 다음의 식이 성립.
위의 과정에 따라 다음의 식이 성립.
 행동 가치 함수를 이용하여 벨만 방정식을 유도하는 과정...
행동 가치 함수를 이용하여 벨만 방정식을 유도하는 과정...
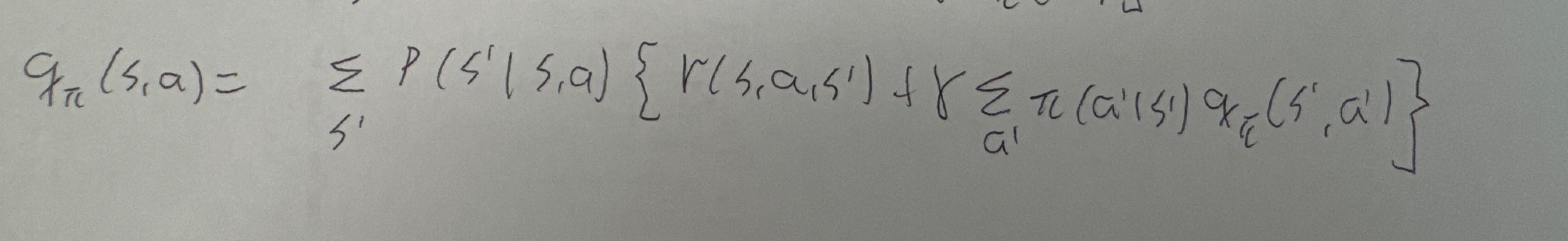 행동 가치 함수를 이용한 벨만 방정식...
행동 가치 함수를 이용한 벨만 방정식...
벨만 최적 방정식 bellman optimality equation
- 우리의 목표는 최적인 정책을 찾는 것이다.
- 최적인 정책: 모든 상태에서 상태 가치 함수가 최대인 정책을 의미.
- 즉, 최적 정책에 대해서 성립하는 것이 벨만 최적 방정식이다.
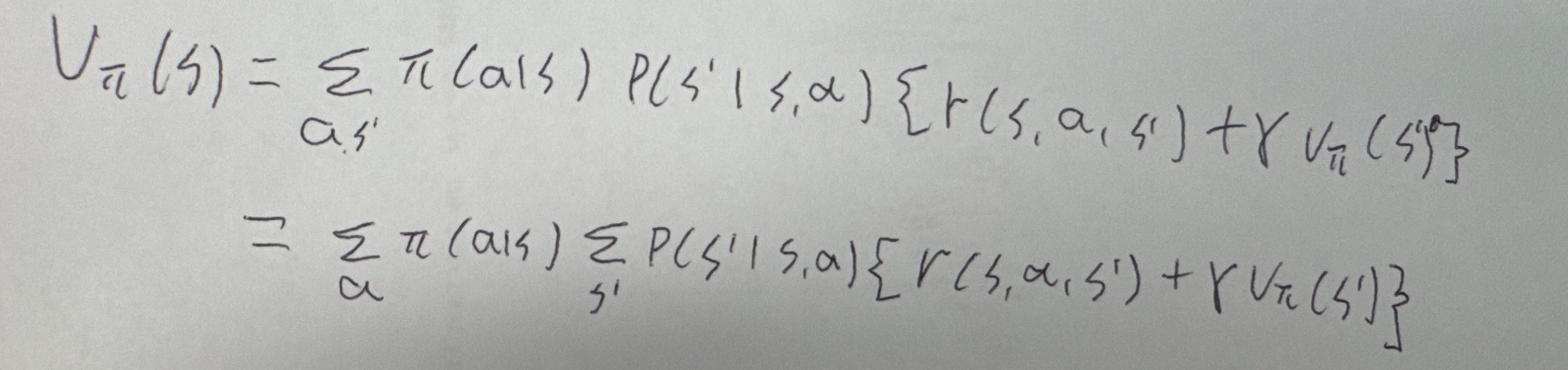 다음은 벨만 방정식이다. ( 상태 가치 함수 )
다음은 벨만 방정식이다. ( 상태 가치 함수 )
- 위의 벨만 방정식에서 최적 정책을 π*( a | s ) 라고 하자. 그러면 v*(s)는 아래의 식과 같다...
 벨만 최적 방정식... 2개의 식 모든 같은 의미...( 상태 가치 함수의 벨만 최적 방정식이다...)
벨만 최적 방정식... 2개의 식 모든 같은 의미...( 상태 가치 함수의 벨만 최적 방정식이다...)
 위의 식은 행동 가치 함수의 벨만 최적 방정식이다.
위의 식은 행동 가치 함수의 벨만 최적 방정식이다.
최적 정책 구하는 방법
- 우선 위에서 벨만 최적 방정식을 바탕으로 최적 행동 가치 함수를 알고 있다고 가정하면, 아래의 식이 성립한다.
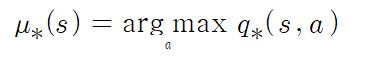 argmax는 최대값을 만들어내는 인수를 반환. a는 action
argmax는 최대값을 만들어내는 인수를 반환. a는 action
 위와 같은 과정을 통하여, 최적의 정책을 구할 수 있다.
위와 같은 과정을 통하여, 최적의 정책을 구할 수 있다.