Demonstration of Memory with a Long Short-Term Memory Network in Python - MachineLearningMastery.com
lstm신경망은 긴 시퀀스에 대하여 학습할 수 있는 반복 신경망의 유형이다.
이것은 차별화한다. 일반적인 다층 신경망이 기억을 가질 수 없고 오직 입력과 출력 패턴만 매핑하는 것을.
작은 고안된 문제에 대한 lstm같은 복잡한 신경망의 기능을 이해하는 것은 중요하며 이것은 너가 네트워크를 크고 심지어 매우 큰 문제로 하는 것은 도와준다.
이 튜토리얼에서, 너는 lstm의 상기하고 기억하는 능력을 발견하게 될 것이다.
이 튜토리얼을 끝맞치고나면 너가 알 수 있는 것:
- 어떻게 rnn의 lstm을 사용하여 작은 시퀀스 예측문제를 풀 수 있는지
- 어떻게 문제를 변환할지, lstm에 학습에 적절히 맞게
- 문제를 올바르게 해결하기 위해 어떻게 lstm을 디자인할지
시퀀스 문제 설명
문제는 한번에 하나의 시퀀스의 값을 예측하는 것 입니다.
시퀀스에 하나의 값이 주어지면, 모델은 다음 값을 예측해야합니다. 예를 들어서, 0이라는 값이 입력으로 주어지면, 그 모델은 1이라는 값을 예측해야 합니다.
여기는 두개의 다른 시퀀스가 있는데 1개는 학습용 1개는 정확히 예측해야하는 것입니다.
하나의 주름은 두 시퀀스 사이에서 정보의 충동이 있으며 모델은 시퀀스 전체를 정확히 예측하기 위해서 알아야하는 것이 있다. 알아야하는 것은 각 단계의 문맥이다.
이 주름은 시퀀스가 모델의 경향을 인지하지 못하는 것을 예방하는데 중요하다, 하나의 단계에서 시퀀스의 각각의 입역-출력 쌍의 값을 기억하는데.
두 개의 학습할 시퀀스들:
- 3,0,1,2,3
- 4,0,1,2,4
우리는 시퀀스의 첫번째 값으로 시퀀스의 마지막까지 반복되는 것을 알 수 있다. 이 지표는 모델이 동작하는 문맥을 제공한다.
두번째 항목에서 마지막 항목으로 전환시에 충들이 있다. 시퀀스1은 2가 주어지면 3이 예측되지만, 반면에 시퀀스2에서는 2가 주어지면 4가 예측되야한다.
이것은 다층 퍼셉트롭과 다른 non-rnn은 학습할 수 없다.
문제 설명
이 섹션은 3가지로 나뉜다.
- 원 핫 인코딩
- 입출력 쌍
- 데이터 재구성
원 핫 인코딩
lstm학습 문제를 위해서 원 핫 인코딩을 쓸 것 이다.
각각의 입력과 출력 값은 5개의 이진 벡터로 표현된다.왜냐면 문제의 알파벳이 5개의 유니크한 값이기 때문이다.
예를 들어 5개의 값을 아래처럼 이진 벡터로 표현한다.
[1, 0, 0, 0, 0]
[0, 1, 0, 0, 0]
[0, 0, 1, 0, 0]
[0, 0, 0, 1, 0]
[0, 0, 0, 0, 1]
우리는 이것을 간단한 함수로 할 수 있다. 시퀀스에 대한 이진 벡터의 리스트를 리턴할 수 있다. 아래 함수의 동작을 구현한다.
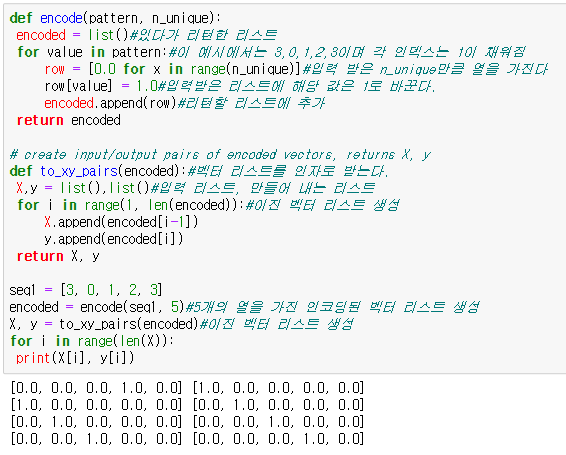
def encode(pattern, n_unique): #입력,특성 수
encoded = list()#빈 리스트 생성
for value in pattern:
row = [0.0 for x in range(n_unique)]
row[value] = 1.0#위에 value에 해당하는 인덱스 값을 1로 바꾼다
encoded.append(row)#리스트에 추가
return encoded
우리는 첫번째 시퀀스와 이진 벤터 리스트의 출력으로 테스트 할 수 있다. 이 예를 끝맞추며 아래같은 리스트다.

입출력 쌍
이 다음 단계는 인코드된 시퀀스를 입력 출력 쌍으로 나누는 것이다.
지도학습은 이와 같은 문제를 대표한다. 이런 머신러닝는 입력 패턴x에서 출력 패턴y로 맵핑되는 문제를 배울수있다.
예를 들어서, 첫번째 시퀀스는 다음 같은 입출력 쌍을 학습한다.
X,y
3,0
0,1
1,2
2,3
날 것의 숫자를 대신해서, 우리는 원 핫 인코딩 된 이진 벡터로 맵핑해서 만들어야한다.
X,y
[0,0,0,1,0][1,0,0,0,0]

데이터 재구성
마지막 단계는 데이터를 재구성하여 LSTM 네트워그가 사용할 수 있게 하는 것 입니다.
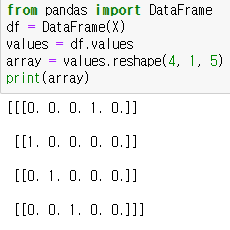
케라스 LSTM은 입력 패턴이 3차원의 넘파이 배열을 가지고 예측합니다.[샘플,타임스텝,특징]
하나의 시퀀스 입력 데이터인 경우, 이 차원은 [4,1,5]이다. 왜냐하면 우리는 4개 행의 데이터와 1개의 타임 스텝 그리고 5개의 열이 있기 때문이다.
우리는 입력 패턴 x리스트로 부터 2차원 넘파이 배열을 만들 수 있다. 그리고 필요로하는 3차원 포맷으로 재구성 할 것이다. 아래 예시를 보자.
우리는 또한 아웃풋 패턴 y도 2차원 넘파이 배열로 변환해야한다.
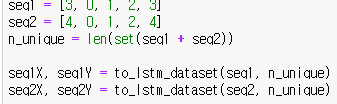
아래의 함수는 시퀀스 알파벳의 크기와 LSTM에서 사용할 준비가된 리턴할 x와 y의 데이터셋을 입력으로 가진다. 이것은 변환을 필요로 하는데, 그 시퀀스가 재구성 되기전의 데이터의 원 핫 인코딩된 입력 출력쌍에 대해서 수행한다.

'di' 카테고리의 다른 글
| MLM블로그 Crash Course in Recurrent Neural Networks for Deep Learning-2 (1) | 2023.03.05 |
|---|---|
| MLM블로그 Crash Course in Recurrent Neural Networks for Deep Learning-1 (0) | 2023.03.04 |
| 코드리뷰 MLM블로그 Demonstration of Memory with a Long Short-Term Memory Network in Python -2 (0) | 2023.03.03 |
| 코드리뷰 lstm 2 (0) | 2023.02.25 |
| 코드리뷰lstm (0) | 2023.02.24 |