강화학습
마르코프 결정 과정
정지홍
2024. 11. 28. 17:00
일회성 과제
- 시작부터 끝이 에피소드 같이 정해져 있는것.
지속적 과제
- 판매량 관리, 로그 관리 같이 끝이 없으며, 계속되는 문제
마르코프 결정 과정 MDP ( markov decision process )
- agent의 action에 따라서 state가 변화하는 문제를 다룸.
- 결정 과정 decision process?
- agent가 action을 결정하는 과정을 의미.
- 만약 [ apple+2 , null , robot , null , bomb-2 , banana+10 ]의 공간이 존재한다고 하자.
- robot은 agent이며, apple과 bomb은 reward이다.
- agent(robot)의 주변을 environment라고 한다.
- agent가 다른 공간으로 이동할때 마다 처해있는 상황이 변화한다. 이를 state상태라고 한다.
- 만약 특정한 시간에 agent가 action을 하려고 하면... ==> '시간'개념을 도입해야함.
- 이때 시간 단위를 time step이라고 한다.
- 위에서 reward를 극대화 하려면 오른쪽으로 +3만큼 이동해야함.
- 즉, 미래의 timestep까지 고려하여 보상의 sum을 극대화 시켜야 함.
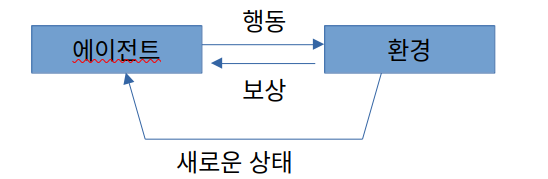
- MDP는 agent와 environment의 상호작용을 수식으로 표현한다.
이를 위해서는 상태전이,보상,정책을 수식으로 표현해야함.- 상태전이 -> 상태를 어떻게 전이할지
- 보상 -> 보상을 어떻게 줄지
- 정책 -> agent는 어떻게 action을 취할지

상태 전이
- 위의 함수를 상태 전이 함수라고 한다. state transition function
- 왼쪽식
- 결정적인deterministic 성질을 지님.
- 오른쪽 식
- 확률적인stochastic 성질을 지님.
- 상태 전이 확률 state transition proability라고도 함.
- 식을 자세히 보면, 과거에 대한 정보는 없으며, 다음 상태를 결정하기 위해서 현재의 상태와 행동만 존재.
이러한 성질은 마르코프 성질 (markov property)이라고 한다.- 마르코프 성질을 만족안할 시에는 과거의 모든 상황 및 상태,행동을 고려해야하며, 이는 계산 비용이 매우 증가함.
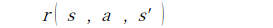
보상 함수
- 위의 보상 함수는 보상이 '결정적'으로 주어진다는 가정을 지닌 함수이다.
- agent가 s상태에서 행동 a를 취하여 s'의 상태가 되었을때 얻는 보상을 의미

에이전트의 정책
- agent가 action을 결정하는 방식이며, 이는 마르코프 성질에 의해서 '현재 상태'만 고려한다.
- 위의 보상 함수와 상태 전이를 보자. 그러면 2개 다 '현재의 상태'만 고려함을 볼 수 있다.
즉, 에이전트의 행동도 '현재 상태'만 고려해서 결정할 수 있다.
- 위의 보상 함수와 상태 전이를 보자. 그러면 2개 다 '현재의 상태'만 고려함을 볼 수 있다.
- 왼쪽식
- 결정적으로 행동을 결정하는 식이다.
즉, 매개변수로 state를 주면 action을 반환한다.
- 결정적으로 행동을 결정하는 식이다.
- 오른쪽 식
- 확률적으로 행동을 결정한다.
즉, state에 대해서 각각 행동 a를 취하는 확률을 의미
- 확률적으로 행동을 결정한다.

수익 return
- agent의 목표는 수익을 극대화 하는 것이다.
- 현재 시간 t에 대해서 수익 Gt는 위의 식과 같다.
- 감마는 할인률이다.
- 이 값은 0.0 ~ 1.0사이의 실수이다.
- 사용하는 이유는 지속적이 과제에서 수익이 무한대까지 늘어나지 않기 위해서 하는것이다.
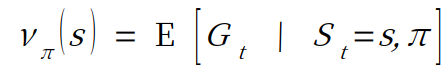

상태 가치 함수 state - value function
- agent와 환경은 '확률적'으로 동작하며, 이에 따라서 action도 확률적으로 결정되며, state도 확률적으로 결정된다.
그렇다면 이로 인한 수익return도 '확률적'으로 달라질것임.- 그래서 어떠한 동작에 대응하기 위해서는 '수익의 기대값'을 지표로 삼아야함.
- v(s)가 수익의 기대값이며, 이를 상태 가치 함수라고 한다. ( 수익의 기대값 = 상태 가치 함수 )
- St는 시간에 따른 상태이며 이는, s와 pi의 값으로 결정됨. pi는 agent의 정책이다.
- 위와 같은 형태의 함수를 상태 가치 함수라고 한다.
- 2번째 식은 에이전트의 정책이 조건으로 주어짐.
- 최적의 정책에서의 상태 가치함수를 최적 상태 가치 함수 optimal state-value function 라고 한다.
- 그리드월드로 보면 각각 칸별로 얼마나 가치가 있는지 판단하는거임
- 즉, 각 칸의 상태 가치 V(s)는 "이 칸에서 시작했을 때, 최적의 정책을 따를 경우 얼마나 좋은 보상을 얻을 수 있는가"를 나타냄
- ex
- 보상이 큰 목표 상태(예: 도착 지점, 보상 지역)에 가까울수록 가치가 높아짐
- 벽이나 장애물로 막혀 있거나 목표와 멀리 떨어진 상태는 가치가 낮아짐
- ==> 출발 지점에서 목표 지점까지 가야 한다고 가정하면, 목표 지점의 V(s)는 가장 높고, 목표 지점에서 멀수록 V(s)는 낮아짐
- 만약에 행동가치라면???
- 행동 가치 함수에서는 만약 내가 (1,1)에서 (1,2)로 움직이는 action을 취하고 최적 정책에 따라서 이어서 행동하는 경우이며 , 그때 (1,2)에서 얻을수 있는 최적의 보상이다.
- 즉, 행동 가치 함수 Q(s,a)는 특정 상태 s에서 행동 a를 선택한 뒤, 그 행동에 따라 도달한 상태에서 최적의 정책을 따를 경우 얻을 수 있는 누적 보상을 계산하는 것이다.
- ex)
- 그리드월드에서 (1,1) 상태에서 (1,2)로 움직이는 행동을 선택했다고 가정하면....
R(s,a)는 이동하였을때 얻는 보상이다. 그리고 (1,2)라는 state에서 최적의 정책을 따른다고 가정할때의 상태가치 함수이다.
- 그리드월드에서 (1,1) 상태에서 (1,2)로 움직이는 행동을 선택했다고 가정하면....